 プチコン 非公式コミュニティ
トピック
プチコン 非公式コミュニティ
トピック
しんいち
◆lHy.hAWXbthn
2019/2/21 23:26
2019/2/21 23:26
情報交換
フォント拡張あれこれ
只今にわかにフォントの拡張手法について色々調べております(ソフトウェアキーボードの関連で)。
プチコンでは、「漢字が表示されな〜い(種類が少ない)」、「文字が小さすぎて読めな〜い」等の状況を打開するために、有志の方々が色々プログラム(ライブラリ)を開発されていますね(感謝しかない)。
私が見かけたプログラム(作者)を挙げておきます。
・プチコン漢字ライブラリ(ほしけんさん)
・漢字フォントライブラリー(あべ れいじさん)
・SFNTフォントライブラリー(すうさん)
・DNL_P(だにえるさん)
・UTIL(なかくんさん)
・NPIME(ナルミンチョさん)
これらを眺めていて何となく分かってきたのは、フォントデータの持ち方(構造)と、そこから文字の画像データを取り出す方法(が要と見て良いかな)に、多少バリエーションはあるものの共通のテクニックがあるようですね。
長くなったので取り敢えずここまで前書き^^;
以降のコメントで、具体的な細かい話をしていこうと思っています。
プチコンでは、「漢字が表示されな〜い(種類が少ない)」、「文字が小さすぎて読めな〜い」等の状況を打開するために、有志の方々が色々プログラム(ライブラリ)を開発されていますね(感謝しかない)。
私が見かけたプログラム(作者)を挙げておきます。
・プチコン漢字ライブラリ(ほしけんさん)
・漢字フォントライブラリー(あべ れいじさん)
・SFNTフォントライブラリー(すうさん)
・DNL_P(だにえるさん)
・UTIL(なかくんさん)
・NPIME(ナルミンチョさん)
これらを眺めていて何となく分かってきたのは、フォントデータの持ち方(構造)と、そこから文字の画像データを取り出す方法(が要と見て良いかな)に、多少バリエーションはあるものの共通のテクニックがあるようですね。
長くなったので取り敢えずここまで前書き^^;
以降のコメントで、具体的な細かい話をしていこうと思っています。
コメント
しんいち
2019/2/23 0:07
◆lHy.hAWXbthn
フォントデータについて。
プチコン標準(とりあえず3号のことだけ考える)では、フォントデータはGRPF(-1)に1文字8×8ピクセルで512×512の範囲に収まっています。これだと文字4096種類分になりますが、実際には幾つかの文字(スペースCHR$(32)とか)で共通のデータを使い回していて、PRINT文で□に×マーク(いわゆる豆腐マーク?)にならずに表示できる文字は4216(だったかな)種類です。英数・記号/JIS第1漢字/プチコン専用文字などが含まれていますが、JIS第2漢字は入っていないんですね。また、文字種類を減らすことなく文字サイズを大きく(16×16とか)しようとすると、512×512の範囲には収まりません。
それで、フォントを拡張しているプログラムでは、1ピクセル1bit、文字サイズ16×16なら256bitの情報で持っています(概ね)。プチコン標準のが1ピクセル16bitで、GRPにそのまま描ける物理色コードの情報であるのに対し、拡張フォントはモノクロですね。これは、データサイズを小さくするためでしょう。ただ、そのモノクロ1ピクセルを配列1要素に格納してしまっては、データサイズが全然小さくならないので、例えば32ピクセル32bit分を整数配列1要素に格納するとか、16ピクセル16bit分を1文字の文字列で格納するとかします(実際にはほぼ後者)。
一旦ここまで(まだ前置きか^^;)。
プチコン標準(とりあえず3号のことだけ考える)では、フォントデータはGRPF(-1)に1文字8×8ピクセルで512×512の範囲に収まっています。これだと文字4096種類分になりますが、実際には幾つかの文字(スペースCHR$(32)とか)で共通のデータを使い回していて、PRINT文で□に×マーク(いわゆる豆腐マーク?)にならずに表示できる文字は4216(だったかな)種類です。英数・記号/JIS第1漢字/プチコン専用文字などが含まれていますが、JIS第2漢字は入っていないんですね。また、文字種類を減らすことなく文字サイズを大きく(16×16とか)しようとすると、512×512の範囲には収まりません。
それで、フォントを拡張しているプログラムでは、1ピクセル1bit、文字サイズ16×16なら256bitの情報で持っています(概ね)。プチコン標準のが1ピクセル16bitで、GRPにそのまま描ける物理色コードの情報であるのに対し、拡張フォントはモノクロですね。これは、データサイズを小さくするためでしょう。ただ、そのモノクロ1ピクセルを配列1要素に格納してしまっては、データサイズが全然小さくならないので、例えば32ピクセル32bit分を整数配列1要素に格納するとか、16ピクセル16bit分を1文字の文字列で格納するとかします(実際にはほぼ後者)。
一旦ここまで(まだ前置きか^^;)。
SatoshiMcCloud
2019/2/23 0:16
◆Z1qfV11i63Jr
続きが気になるので、コメ残し
若干違う話になるかもしれませんが、GPUTCHR16の命令はBIG専用になってますが、別に3号で使えてもいいと思うんですよね。
若干違う話になるかもしれませんが、GPUTCHR16の命令はBIG専用になってますが、別に3号で使えてもいいと思うんですよね。
しんいち
2019/2/23 1:34
◆lHy.hAWXbthn
3号にGPUTCHR16を搭載するとなると、まず1024×1024のGRPFが必要になり、FONTDEFやWIDTHも16対応しなきゃならないしで、大掛かりになって難しかったんだと思います(メモリも厳しそう)。漢字も8×8でしか見れないとなると、気持ちは分かりますけどね。
しんいち
2019/2/23 2:03
◆lHy.hAWXbthn

フォント画像(16×16)を、色があるところを1、ないところを0とした2進数で考えて、その数値を文字コードとした文字に変換し、最終的には1文字分のフォントデータを16文字で格納。プチコンで有効な文字コードは16bit(65535)まで。その文字コードの文字がPRINT文で豆腐になろうが関係ないので、その手のプログラムでは大抵、豆腐だらけのやたらに長い文字列が書かれることになるのです。
だにえる
2019/2/23 3:22
◆m76OCAQyrWGt
(↓宣伝含む)
検証はしてないけど、少なくとも[フォント拡大倍率1*1でアンチエイリアス無し]って条件ならDNL_Pが一番速いと思う。
コードの可読性ほぼ無視して、徹底的な速度重視してるし。
メモリは3号の半分か、1/4かを覚えてないけど消費する。
ほしけん氏のライブラリが元になっていて、縁取り、アンチエイリアス、文字詰め機能を省いて、3倍以上の速度向上と、以下の表現が出来るようにした。
斜体、文字間隔、(90度単位の)回転、文字の反転、オーバーレイ、フォントデータの0と1の反転....等。
DATA文の読み込みも最速かもしれない。(リテラルで代入してあるのには負ける)
実は24*24アンチエイリアス固定フォントに特化して、より爆速になったバージョンも存在する。
プチコン4で文字描画ライブラリ作るとしたら、同時に複数種類のフォントを扱えるやつとか、疑似ベクターフォントとかも一応考えにはある。GRPの透明度の扱いがどう変わってるかにもよるけど。
検証はしてないけど、少なくとも[フォント拡大倍率1*1でアンチエイリアス無し]って条件ならDNL_Pが一番速いと思う。
コードの可読性ほぼ無視して、徹底的な速度重視してるし。
メモリは3号の半分か、1/4かを覚えてないけど消費する。
ほしけん氏のライブラリが元になっていて、縁取り、アンチエイリアス、文字詰め機能を省いて、3倍以上の速度向上と、以下の表現が出来るようにした。
斜体、文字間隔、(90度単位の)回転、文字の反転、オーバーレイ、フォントデータの0と1の反転....等。
DATA文の読み込みも最速かもしれない。(リテラルで代入してあるのには負ける)
実は24*24アンチエイリアス固定フォントに特化して、より爆速になったバージョンも存在する。
プチコン4で文字描画ライブラリ作るとしたら、同時に複数種類のフォントを扱えるやつとか、疑似ベクターフォントとかも一応考えにはある。GRPの透明度の扱いがどう変わってるかにもよるけど。
こういち
2019/2/23 17:24 ネタバレ
◆ou0jbJnEJ0Kb
こういち
2019/2/23 17:36 ネタバレ
◆ou0jbJnEJ0Kb
しんいち
2019/2/23 21:58
◆lHy.hAWXbthn
>だにえるさん
作者からコメント頂けるのは非常にありがたい(^o^)
DNL_Pのファイルサイズが大きかったのは、速度重視によるものかな。
プチコン4でははじめからJIS第2漢字やIMEが使えたら楽なのになぁと思う一方、はじめから色々便利だとツール作ろうって気になるか心配。
>こういちさん
フォントデータからGRP用配列に戻して描画するのは、グラフィック配列(ビットテーブル)をGLOADするのがよく使われてる手のようです。ただ、ビットパターンを予め65536種類用意しようとすると、ビットテーブルの配列サイズが65536×16と巨大になってしまうため、256種類(サイズ256×8)のビットテーブルを用意して、8bitずつ2回に分けて取り出しているようです。
作者からコメント頂けるのは非常にありがたい(^o^)
DNL_Pのファイルサイズが大きかったのは、速度重視によるものかな。
プチコン4でははじめからJIS第2漢字やIMEが使えたら楽なのになぁと思う一方、はじめから色々便利だとツール作ろうって気になるか心配。
>こういちさん
フォントデータからGRP用配列に戻して描画するのは、グラフィック配列(ビットテーブル)をGLOADするのがよく使われてる手のようです。ただ、ビットパターンを予め65536種類用意しようとすると、ビットテーブルの配列サイズが65536×16と巨大になってしまうため、256種類(サイズ256×8)のビットテーブルを用意して、8bitずつ2回に分けて取り出しているようです。
こういち
2019/2/24 10:34
◆ou0jbJnEJ0Kb
なるほど。
で、スキューはシフトすればいいし、縁取りやアンチエイリアスはシフトとORすれば行ける感じなのかな?
で、スキューはシフトすればいいし、縁取りやアンチエイリアスはシフトとORすれば行ける感じなのかな?
しんいち
2019/2/24 20:07
◆lHy.hAWXbthn
文字のエフェクトについてはまだ全然考えてない。
当面の目標は、拡張したフォントでのGPUTCHR相当の機能です(拡大面倒そうだから省略かな)。ずっと、フォントデータの持ち方と取り出し方ばかり考えてて実際の描画を中々試さないと言う(人のソース眺めるばかり)^^;
当面の目標は、拡張したフォントでのGPUTCHR相当の機能です(拡大面倒そうだから省略かな)。ずっと、フォントデータの持ち方と取り出し方ばかり考えてて実際の描画を中々試さないと言う(人のソース眺めるばかり)^^;
しんいち
2019/2/25 0:03
◆lHy.hAWXbthn
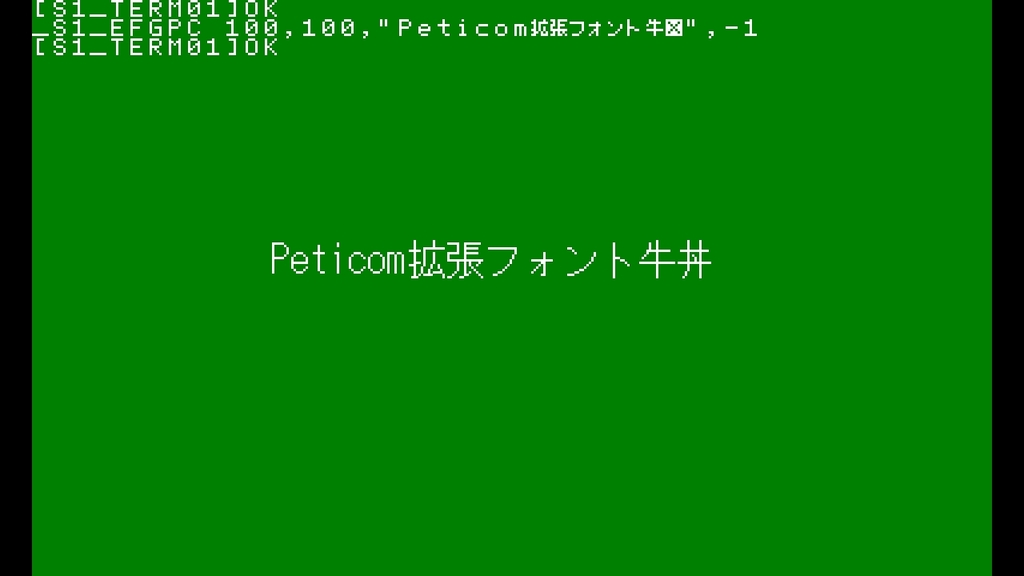
KNJLIBをベースにちょこちょこ改良してみました。あとで解説とかしてみたいと思います。
しんいち
2019/2/25 20:29
◆lHy.hAWXbthn
現状について。
フォントデータは、元(KNJLIB)では4つ(半角/全角非漢字/JIS第1漢字/JIS第2漢字の文字列配列4つ)に分けられていたのを半角と全角の2つ(文字列配列2つ)に(くっ付けただけ)。また、フォントデータから該当文字のデータを探す際、元ではフォントデータと同じ並びの文字列配列を用意しINSTRで位置を調べていたのを、文字コード→データ位置を直接知るための整数配列(インデックステーブル)を用意(要素数は文字コード(65536)分)。データ位置はフォントの存在する文字種(7120)分ソースに直接代入文を記述(7120行^^;)。インデックステーブル65536要素分メモリ使うけど、INSTR用の文字列(長さ7120)が不要になるから良し(と自分に言い聞かせる)。これでフォントデータ位置の検索処理を軽減。起動時の初期化処理も直接代入文作戦でそれほど遅くないはず。但しファイルサイズは大きくなりました。
これから試そうとしているのは、フォントデータを文字列じゃなく整数配列(DATA文か)に。32ピクセル32bitを1要素にできるので要素数削減に。でもやっぱりファイルサイズ大きくなりそう(でも実行中のメモリとは関係ないみたいだし)。あと、フォントデータのbitの並びを左右逆に(した方が若干効率良いような)。
描画処理は今のところ普通(ビットテーブルから16ピクセル分ずつ取り出して画像1文字分になったらGLOAD)。
フォントデータは、元(KNJLIB)では4つ(半角/全角非漢字/JIS第1漢字/JIS第2漢字の文字列配列4つ)に分けられていたのを半角と全角の2つ(文字列配列2つ)に(くっ付けただけ)。また、フォントデータから該当文字のデータを探す際、元ではフォントデータと同じ並びの文字列配列を用意しINSTRで位置を調べていたのを、文字コード→データ位置を直接知るための整数配列(インデックステーブル)を用意(要素数は文字コード(65536)分)。データ位置はフォントの存在する文字種(7120)分ソースに直接代入文を記述(7120行^^;)。インデックステーブル65536要素分メモリ使うけど、INSTR用の文字列(長さ7120)が不要になるから良し(と自分に言い聞かせる)。これでフォントデータ位置の検索処理を軽減。起動時の初期化処理も直接代入文作戦でそれほど遅くないはず。但しファイルサイズは大きくなりました。
これから試そうとしているのは、フォントデータを文字列じゃなく整数配列(DATA文か)に。32ピクセル32bitを1要素にできるので要素数削減に。でもやっぱりファイルサイズ大きくなりそう(でも実行中のメモリとは関係ないみたいだし)。あと、フォントデータのbitの並びを左右逆に(した方が若干効率良いような)。
描画処理は今のところ普通(ビットテーブルから16ピクセル分ずつ取り出して画像1文字分になったらGLOAD)。
まるだい
2019/2/25 20:55
◆AdwyE6qhnxpV
"丼"は豆腐になるのか
しんいち
2019/3/1 0:33
◆lHy.hAWXbthn

比較項目(列)は、左から
・EXEC ファイルにかかった時間(EXEC.F)
・EXEC スロットにかかった時間(EXEC.S)
・LOAD ファイルにかかった時間(LOAD)
・USE スロットにかかった時間(USE)
・文字描画にかかった時間(PRINT)
・メモリ消費量(MEM)
プログラムの種類は
H):KNJLIB
0):KNJLIBベースの、フォント検索高速化(INSTRを1回のみに)
1):0)の、INSTRをインデックス配列参照にして高速化(配列代入文大量)
2):1)の、フォントデータ(長い文字列)を2文字1整数のDATA文に(ファイル巨大)
3):2)の、DATA文(整数配列)を、DATファイルに(LOADして使用)
4):3)の、ビットテーブル(描画の元になる配列)を256→65536に(やりすぎ^^;)
D):DNL_P
S):1)の、インデックス代入文直接記述をやめて素直にループに
起動(初期化)時間に関する比較項目が無駄に多いけど、短い時間で起動/終了を繰り返すような使い方(IMEとか)をする時に気になるかと思って。
考察。
フォント検索をINSTRからインデックス配列参照にすると、メモリ消費量2倍で描画時間半分くらい。どちらを優先するかだな。フォントデータを整数配列(1要素で32ピクセル)にしても、文字描画の時間はほとんど変わらない(結局8ビットずつ処理してるからか)。但し、ビットテーブルを65536にすると、16ビットずつ処理できるのでかなり速い。でもメモリ使い過ぎ。
起動時間には結構差が出てるが、それはデータの構造とか持ち方とかよりも、結局ファイルサイズが小さい方が速いみたい(直接代入文作戦は失敗)。
それにしてもDNL_Pの文字描画は普通に速い。
あまさとしおん
2019/3/1 19:13
◆mzDKTVUAtwqE
久しぶりに見たけど、KNJLIBのフォント検索高速化は良さそうなので取り入れてみようかなと思ったり
表計算でたくさんのセルの結果が一気に変わるときは描画量多くなるしなー
表計算でたくさんのセルの結果が一気に変わるときは描画量多くなるしなー
しんいち
2019/3/2 14:53
◆lHy.hAWXbthn
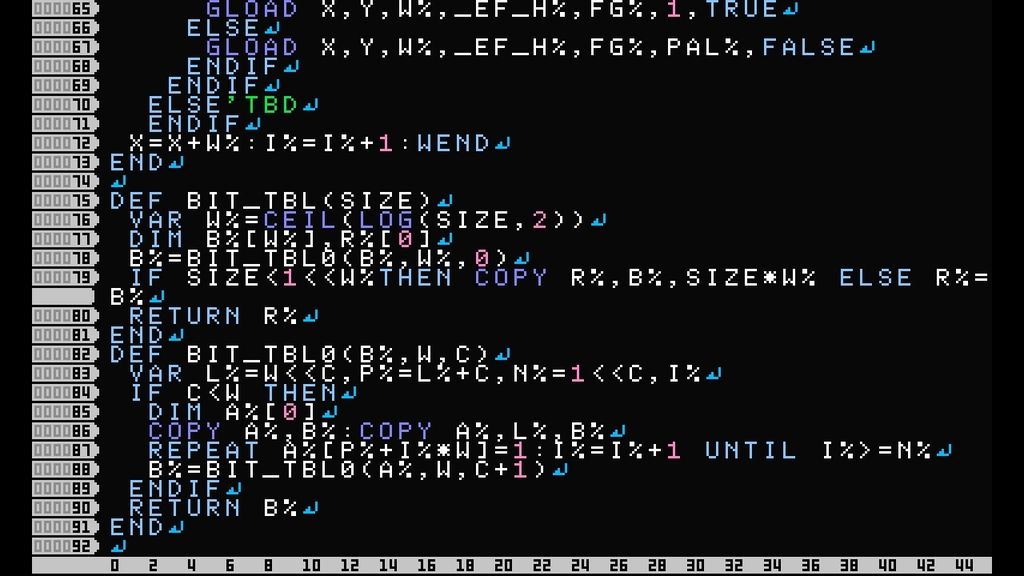
256のビットテーブルを作る場合、256×8回ループさせるより効率が良いと思う。仕組みは、倍倍で配列をコピーしていって、増えた桁のところにだけ1を代入(B%[0〜7]をB%[8〜15]にコピーしてB%[8]=1、B%[0〜15]をB%[16〜31]にコピーしてB%[17]=1:B%[25]=1、・・・)。
ビットテーブルは初期化時に一度だけ作れば良いので、これを高速化したところで効果は薄い^^;
なお、スクショのプログラムは、ビットテーブルの配列順番と2進数の桁数を一致(見た目は2進数が左右逆転)させたバージョン。KNJLIBのフォントデータに適用する場合は、83行目の
P%=L%+C
を
P%=L%+W-1-C
にすればよいでしょう。
DEF2つありますが、BIT_TBL0単体だけでも使えます。256のビットテーブルを作成する場合は
DIM B%[8]:B%=BIT_TBL0(B%,8,0)
何か分かりにくいかと思ってBIT_TBL被せてみました。BIT_TBLの場合は
DIM B%[0]:B%=BIT_TBL(256)
しんいち
2019/3/3 12:42
◆lHy.hAWXbthn
KNJLIBのフォントには、\(バックスラッシュ)CHR$(127)の半角と全角、〜(チルダ)CHR$(126)の全角が入ってなかったので追加。同じ種類のフォントの似た文字(/スラッシュとか)を一旦0,1のDATA文に落として、EDITモードで修正した後、データ文字列に変換してフォントデータに追加。数が多かった(フォント全種類分で120個くらい)ので手修正が苦行でした^^;
ついでにビットの並びを左右反転(2進数の桁数を配列順番通りに)。その方が気持ちいいので(^^ゞ
フォントデータを超長い文字列にした時に、同じ文字が連続してたら"@"*11とかCHR$(10)*2とかして、ソースコード上の長さを短縮。これでファイルサイズを少し小さくできた。
さて、こうしてできたフォントデータを、プログラムに参照させる形式?をどうしようか検討中。KNJLIBではCOMMON DEFを介してグローバル変数に代入。これはプログラムとフォントデータが違うスロットに置かれても大丈夫なようにだと思うけど、1つのプログラム(同じスロット)にマージした場合はCOMMON DEFを介すのは冗長なので、直接代入文を記述した方が良い(からコピペしてからちょっと記述変更する)。DNL_PではDATA文で持っているので、同じスロット内にあろうと別スロットに置こうと、RESTOREにラベル指定してREADすれば良いから分かりやすい(DATA文にCHR$(10)とかは書けないけどその辺工夫されているよう)。但し、直接代入よりはちょっと遅いのかな。他、TXT形式やDAT形式の完全別ファイルで持っているものもあるけど、1ファイルにできる選択肢がないと、必ずLOADが必要になって起動時間を速くできない(素直なやり方だと思うけど、プチコンでは遅いんだよねぇ)ので今回それらの方法は採らない。
どうしようかなぁ
ついでにビットの並びを左右反転(2進数の桁数を配列順番通りに)。その方が気持ちいいので(^^ゞ
フォントデータを超長い文字列にした時に、同じ文字が連続してたら"@"*11とかCHR$(10)*2とかして、ソースコード上の長さを短縮。これでファイルサイズを少し小さくできた。
さて、こうしてできたフォントデータを、プログラムに参照させる形式?をどうしようか検討中。KNJLIBではCOMMON DEFを介してグローバル変数に代入。これはプログラムとフォントデータが違うスロットに置かれても大丈夫なようにだと思うけど、1つのプログラム(同じスロット)にマージした場合はCOMMON DEFを介すのは冗長なので、直接代入文を記述した方が良い(からコピペしてからちょっと記述変更する)。DNL_PではDATA文で持っているので、同じスロット内にあろうと別スロットに置こうと、RESTOREにラベル指定してREADすれば良いから分かりやすい(DATA文にCHR$(10)とかは書けないけどその辺工夫されているよう)。但し、直接代入よりはちょっと遅いのかな。他、TXT形式やDAT形式の完全別ファイルで持っているものもあるけど、1ファイルにできる選択肢がないと、必ずLOADが必要になって起動時間を速くできない(素直なやり方だと思うけど、プチコンでは遅いんだよねぇ)ので今回それらの方法は採らない。
どうしようかなぁ
しんいち
2019/3/4 20:39
◆lHy.hAWXbthn
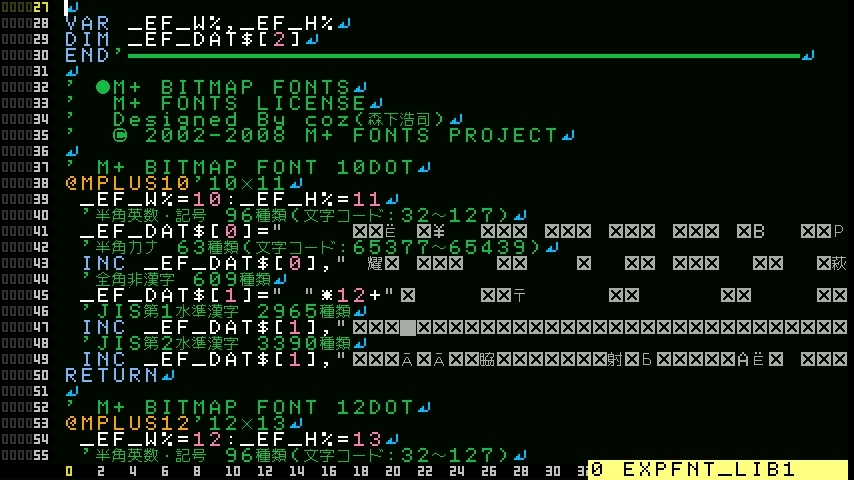
COMMON DEF SLOT_LIB S,LB$
VAR SH$=CHR$(S+48)+":"
GOSUB SH$+LB$
_EF_W%=VAR(SH$+"_EF_W%")
_EF_H%=VAR(SH$+"_EF_H%")
_EF_DAT$=VAR(SH$+"_EF_DAT$")
END
フォントデータをスロット1に置く場合は下記のようにする。
EXEC"1:EXPFNT_LIB1"
SLOT_LIB 1,@SHINONOME16
試したら動いてるようだけど、こんなことして大丈夫なんだろうか^^;
しんいち
2019/3/11 0:20
◆lHy.hAWXbthn
プチコン専用文字(Aボタンのアレとか)の追加とか考えてたら、見た目同じ文字が結構あるみたいなので、複数の文字で共通のフォントデータを参照できるような仕組み(リンク的な)を試したくなった(データも短縮できそう)。で、試したら結局ファイルサイズが大きくなるはめに。
仕組み上、確かにフォントデータ自体は短くできたんだけど、フォント種類によって見た目が同じになる文字の種類が異なることがあるので、フォントデータの並び(インデックス)を共通で持つことができなくなり、フォント種類毎にインデックス文字列も一緒に指定しなくちゃならなくなって、これが結構デカかったよう。
ただ、インデックス文字列を全フォント共通で1つだけ持つよりも色々便利になりそうなので、これでもうちょっと進めてみようと思う。しかし、このリンク的な仕組みへのファイル変換を行うプログラム、BIGで実行しても30分位かかる(3号だと、恐ろしい^^;)。
仕組み上、確かにフォントデータ自体は短くできたんだけど、フォント種類によって見た目が同じになる文字の種類が異なることがあるので、フォントデータの並び(インデックス)を共通で持つことができなくなり、フォント種類毎にインデックス文字列も一緒に指定しなくちゃならなくなって、これが結構デカかったよう。
ただ、インデックス文字列を全フォント共通で1つだけ持つよりも色々便利になりそうなので、これでもうちょっと進めてみようと思う。しかし、このリンク的な仕組みへのファイル変換を行うプログラム、BIGで実行しても30分位かかる(3号だと、恐ろしい^^;)。
しんいち
2019/3/27 13:16
◆lHy.hAWXbthn

で、せっかく拡張フォント使ったのにGPUTCHRじゃないと描けない文字があるのは残念なので、プチコン専用文字のフォントも作ってみる(とりあえず14×14を、NPIMEを参考にしてGPUTCHR16の出力と見比べながらお絵描きツールでちまちまと)。行番号のフォントは4色(透明+3色)使われてて面倒だったけど、意地で実現(4進数(1ピクセル2bit)テーブルを作成。かなりメモリ消費^^;)。
こうなったらNintendo外字も作っちゃおうかなぁということで、DIALOGのスクショを載せておく(これ見ながらお絵描きツールでちまちま。GamePadとかWiiリモコンとか、むずい)。
- 1
- 2
コメントを書く
- こちらは「プチコン3号」「プチコンBIG」など、プチコンシリーズに関する話題を扱ったコミュニティです
- プチコンシリーズにまったく関係ない書き込みはご遠慮下さい。削除の対象となります
- こちらにはその他のゲームや雑談のコミュニティはなく、作る予定もありません (ひとりで管理できないため)。ごめんなさい
- ユーザー登録なしで書き込みができます
- 秘密の合い言葉は成りすましの防止 (トリップ機能)、書き込みの編集時の本人認証に使用します
- 秘密の合い言葉に他人に推測されやすい言葉、他サービスと同じパスワードは入力しないでください。
- 書き込むと、投稿時に入力したお名前と秘密の暗号が記憶され、ログイン状態になります